Request Google Search Indexing for GitHub Pages + Jekyll
Hi there ![]()
This site (at least at the moment of writing) is powered with the GitHub Pages + Jekyll combo. But there’s a catch: the posts are not automatically indexable by the search engines (aka Google Search since it’s the leader in the field) unlike, for example, posts on the Google Blogger platform. Because of this, your site’s content may not be easily discoverable through the ordinal usage of search engines.
Should we give up and move all the content to another platform that handles all the magic behind the scenes for us?
Not necessarily.
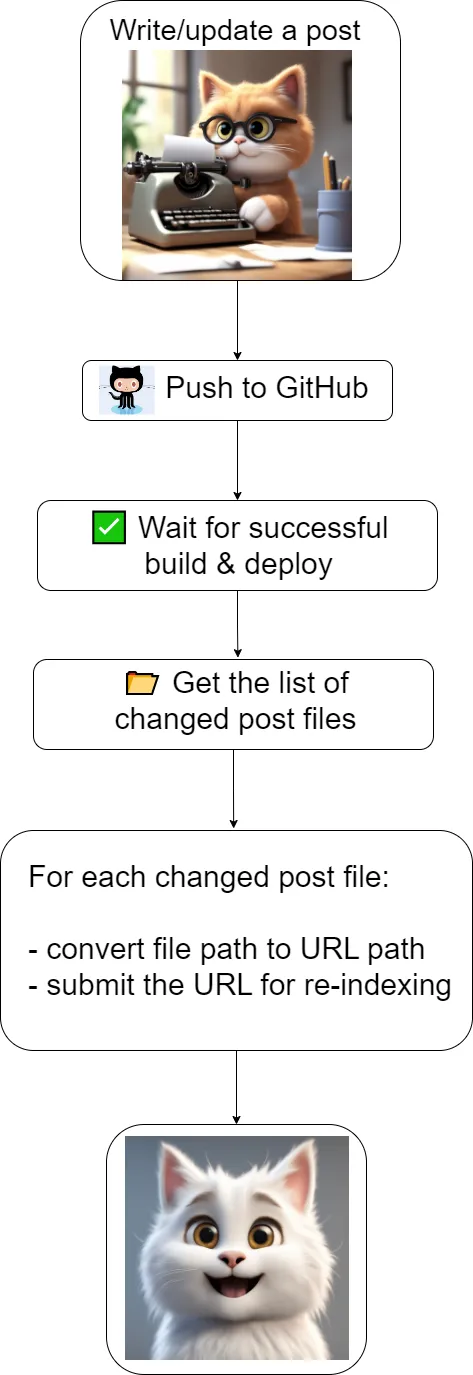
To improve the situation, I’ve put my DevOps hat on and wrote a GitHub Actions workflow to help. And the basic steps are the following:
-
To ask Google Search Indexing to crawl / re-index your posts you have to register on the Google Search platform and verify the ownership of the domain that you use for the website (I’m using a custom domain so I’ve already completed this step a long time ago), as well as enable the Indexing API in the GCP project, and connect service account from GCP project to the Search Console for your website.
-
It’s quite a broad topic on its own so I won’t copy-paste the steps from the Google documentation here for a couple of reasons:
- there are a lot of possible options to look at
- and those options are subject to change by the vendor (Google)
- so it’s always better to consult the up-to-date docs on
-
At the end of the setup flow you should end up with a JSON file that would serve as a key for authorizing your requests to the Google Search Indexing API
-
anonymized sample of the file’s structure:
{ "type": "service_account", "project_id": "your-blog-project", "private_key_id": "666", "private_key": "-----BEGIN PRIVATE KEY-----\nLoremIpsum42=\n-----END PRIVATE KEY-----\n", "client_email": "your-indexing-service-account@your-blog-project.iam.gserviceaccount.com", "client_id": "42", "auth_uri": "https://accounts.google.com/o/oauth2/auth", "token_uri": "https://oauth2.googleapis.com/token", "auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs", "client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/your-indexing-service-account%40your-blog-project.iam.gserviceaccount.com", "universe_domain": "googleapis.com" }
-
-
-
Create a workflow that:
-
runs after successful completion of the build & deployment of the website (obviously, your site updates should be live before requesting re-indexing)
-
actually, it was not clear how to do it properly because by default GitHub Pages + Jekyll websites are built and deployed automatically by some default presets from GitHub Pages, and among the site repository’s files you won’t find the corresponding GitHub workflows by default.
So, the question is: whether the addition of the explicit workflow to the repo will break/cancel the implicitly provided build + deploy workflow (in which case we would have to manually reproduce the similar functionality) or not.
After investigation and testing the answer is: the default build + deploy will still be active so there’s no need to reinvent the wheel.
Curious readers may find the default workflows here: Starter Workflows
-
-
gets the list of all the changed post files in the latest commit
- looks up the files by pattern
_posts/**.md
- looks up the files by pattern
-
converts the file path into the URL path for each changed post file
-
for simplicity I’ve manually made the conversion only for simple posts which mimics the Jekyll’s translation logic since currently that’s the only kind of posts that I use
- e.g.
_posts/2022-03-20-hello-world.md=>2022/03/20/hello-world.html
- e.g.
-
but actually, Jekyll has more options for mapping the post files to URLs, for example, the usage of categories may alter the output
-
-
submit each URL of the changed post to the Google Search Indexing API asking it to re-index
-
{ "url": "https://blog.tricky.cat/2022/03/20/hello-world.html", "type": "URL_UPDATED" }
-
-
and voila: after some time your page will be reindexed
- specific time to wait depends on the internal mechanics of the Google Search Engine and is out of our control
High-level flow
GitHub Workflow:
name: post-succeeded-deployment-workflow
run-name: 🚀 ${{ github.actor }} runs a post succeeded deployment workflow
on:
# Run this workflow after a succeeded build & deploy
workflow_run:
workflows: ["pages-build-deployment"]
types:
- completed
jobs:
request-google-search-indexing-for-changed-posts:
runs-on: ubuntu-latest
# 😊 Run this job only if the triggering workflow succeeded (and not just completed)
if: ${{ github.event.workflow_run.conclusion == 'success' }}
steps:
- uses: actions/checkout@v4
- name: Get all post files that have changed
id: changed-files-yaml
uses: tj-actions/changed-files@v41
with:
files_yaml: |
post:
- _posts/**.md
- name: Setup Python
if: steps.changed-files-yaml.outputs.post_any_changed == 'true'
uses: actions/setup-python@v4
with:
python-version: '3.11.3'
- name: Request Google Search re-indexing of the changed posts
if: steps.changed-files-yaml.outputs.post_any_changed == 'true'
env:
ALL_CHANGED_POST_FILES: ${{ steps.changed-files-yaml.outputs.post_all_changed_files }}
BLOG_BASE_URL: ${{ vars.BLOG_BASE_URL }}
GOOGLE_SEARCH_INDEXING_API_KEYFILE: ${{ secrets.GOOGLE_SEARCH_INDEXING_API_KEYFILE }}
run: |
echo -e "List of all the post files that have changed:\n$ALL_CHANGED_POST_FILES\n"
pip install oauth2client==4.1.3
python ./.github/workflows/scripts/posts-google-search.py
Notes:
-
pages-build-deploymentis the name of the default (provided by GitHub) workflow that takes care of building and deploying the website on commits to the main branch -
workflow runs only after the build & deploy workflow is finished successfully
-
obviously, it uses the site-specific info via:
Variables BLOG_BASE_URLhttps://blog.tricky.catSecrets GOOGLE_SEARCH_INDEXING_API_KEYFILEThe contents of the JSON file for the Google Search Indexing API
Python script:
from oauth2client.service_account import ServiceAccountCredentials
import httplib2
import os
import json
GOOGLE_SEARCH_INDEXING_API = {
'SCOPES' : [ "https://www.googleapis.com/auth/indexing" ],
'ENDPOINT': "https://indexing.googleapis.com/v3/urlNotifications:publish",
'KEYFILE': None
}
try:
GOOGLE_SEARCH_INDEXING_API['KEYFILE'] = json.loads(os.environ['GOOGLE_SEARCH_INDEXING_API_KEYFILE'])
ALL_CHANGED_POST_FILES = os.environ['ALL_CHANGED_POST_FILES'].split(' ')
BASE_URL = os.environ['BLOG_BASE_URL']
# Drop trailing slash if any
if BASE_URL[-1] == '/':
BASE_URL = BASE_URL[:-1]
except:
print(f'Some required env vars were not resolved 👿')
exit(1)
# '_posts/2022-03-20-hello-world.md' => '2022/03/20/hello-world.html'
def postFilePathToUrlPath(s: str):
return (s.replace('_posts/', '')
.replace('-', '/', 3)
.replace('.md', '.html'))
credentials = ServiceAccountCredentials.from_json_keyfile_dict(GOOGLE_SEARCH_INDEXING_API['KEYFILE'], scopes=GOOGLE_SEARCH_INDEXING_API['SCOPES'])
http = credentials.authorize(httplib2.Http())
def submitRequest(absoluteUrl: str):
reqBody = f"""{{
"url": "{absoluteUrl}",
"type": "URL_UPDATED"
}}"""
print(f'Request to be submitted:\n{reqBody}')
respHeaders, respBody = http.request(GOOGLE_SEARCH_INDEXING_API['ENDPOINT'], method="POST", body=reqBody)
print(f'Response headers: {respHeaders}')
print(f'Response body: {respBody}')
for postFile in ALL_CHANGED_POST_FILES:
if not postFile: continue
print('\n-----------------\n')
relativeUrl = postFilePathToUrlPath(postFile)
absoluteUrl = f'{BASE_URL}/{relativeUrl}'
print(f'Post file: {postFile}')
print(f'Relative URL: {relativeUrl}')
print(f'Absolute URL: {absoluteUrl}')
submitRequest(absoluteUrl)
print('\n-----------------\n')
Live Code on GitHub
Possible Improvements:
- add support for more kinds of Jekyll links
- switch to using the batch API requests
- possibly keep track of the daily API usage limits for sites with lots of frequent updates
![]()